

法国里昂商学院教授Guillaume Coqueret:金融学中的监督学习技术综述
首席数字官
2020-12-18
文丨张齐齐 编辑丨秦丽
来源丨首席数字官
2020年12月12日,“2020中国数字化年会线上论坛”之【法国里昂商学院全球商业智能论坛】圆满举行。论坛聚焦世界领先的智慧商业运营,并就智能制造、数字化转型过程中的创新技术、相关管理学前沿理论与实践的问题展开深度交流。
对于金融行业,大约有五个领域可以运用人工智能,包括任务自动化、客户关系管理(尝试改善应对客户、与客户打交道的方式,例如使用聊天机器人、减少客户流失等等)、信用评分、欺诈检测和资产分配。论坛上,法国里昂商学院金融与数据科学教授Guillaume Coqueret以“金融学中的监督学习技术”为主题,为大家重点介绍了后三个领域的用例。本文由【首席数字官】总结,提炼演讲嘉宾的精华观点编辑而成,欢迎阅读和分享。

一、信用评分

信用评分是银行或金融机构的要求或需求,因为其业务是贷款给个人或公司。信用评分流程十分复杂,必须确保在为个人或公司批准贷款时,所提供的服务和所面临的风险相匹配。为了实现这个目标,需要分析有关借款个人或机构的大量数据,也需要收集大量数据。例如,对于个人而言,包括个人的年龄、薪资、财富状况以及关于以前贷款历史的大量数据,比如这个人是否按时还款、是否曾经拖欠还款、违约历史记录情况如何等。对于公司来说,也是如此,但是可能需要访问其他类型的数据。例如会计数据,公司的营业收入、债务情况、财务比率等,需要评估申请贷款的公司实体的总体状况。这代表了大量数据,所以运用监督学习背后的理念是自动化以及定量挖掘数据,从而协助了解概况和风险。
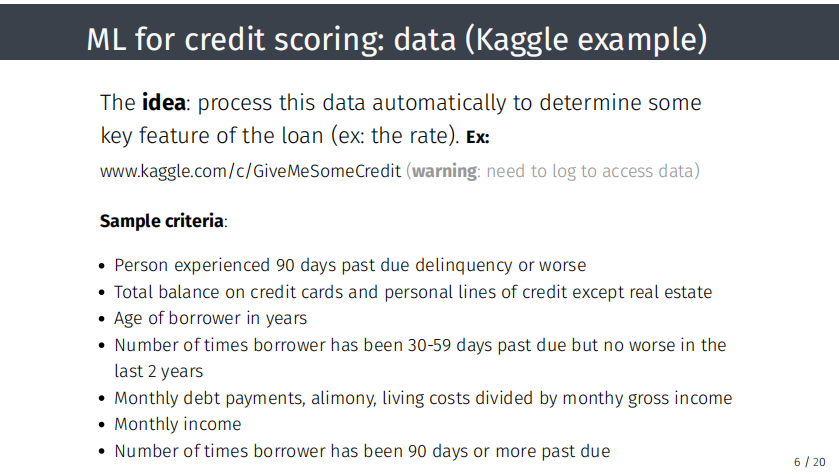
例如,Kaggle上的数据集。 Kaggle是一个网络平台,提出机器学习领域的挑战,并且至少存在一个与信用评分有关的挑战。用户登录Kaggle平台,就可以访问数据,查看在机器学习中使用的数据类型。每个人拖欠还款的历史,即该人员是否拖欠还款90天以上,以及该人员在以往贷款乃至当前贷款中的表现的数据都展示出来。每行数据都代表一名客户,所有列均为客户的特征。然后,使用这些数据来尝试构建算法,以确定是否要向新客户或现有客户授予贷款。
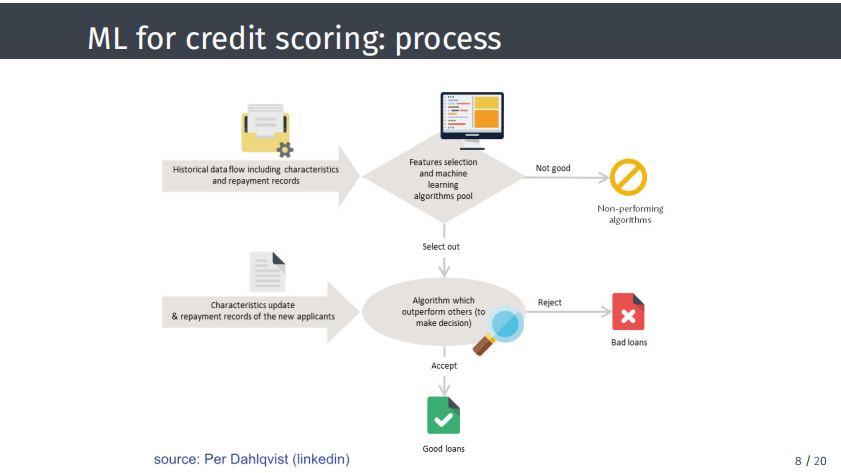
如果授予贷款,采用何种利率同样重要。该算法的输出之一通常是违约概率或给定违约损失,这是该行业常用的经典KPI。 这个过程很简单。首先要拥有大量数据,或者可以获取外部数据,据此可以构建一系列算法或一个算法。有了新客户或新数据,就可以丰富数据库,可以用来决定是否要向某个特定客户贷款。如果概况资料不匹配,则拒绝贷款;如果概况资料匹配,则批准贷款。

信用评分领域存在哪些问题?就这些技术而言,就像机器学习中经常出现的情况,偏差是一大问题。要确保自己的算法是公平的,不会导致性别、种族或其他歧视。另一点则是可解释性,因为在机器学习中,工具犹如黑匣子。若想准确地了解算法在做什么,为什么会做出某个特定决定,需要求助于其他类型的工具,包括可解释的AI工具。而同时,AI工具大量存在,必须能够理解算法在做些什么,理解为什么计算机或算法会做出特定决定,这一点至关重要。
二、欺诈检测
欺诈主要分为两种类型。第一种欺诈很明显,即一家金融机构(例如银行)遭受欺诈,可能是由于黑客攻击,或人们丢失了信用卡,而坏人利用信用卡进行在线购买,或从银行账户中取走资金。这种情况会导致客户不满意,金融机构也希望对抗欺诈性的数据使用者。第二种欺诈是报告欺诈,这种欺诈不常见。报告欺诈指无论是否自愿,公司产生存在错误的文档,可能是会计文档或行政文档。如果并非自愿产生,那只是错误;如果是自愿产生,那就属于真正的欺诈。这种情况很糟糕,因为有时其他人可能会使用这些文档来做出重要决定,例如投资决定。
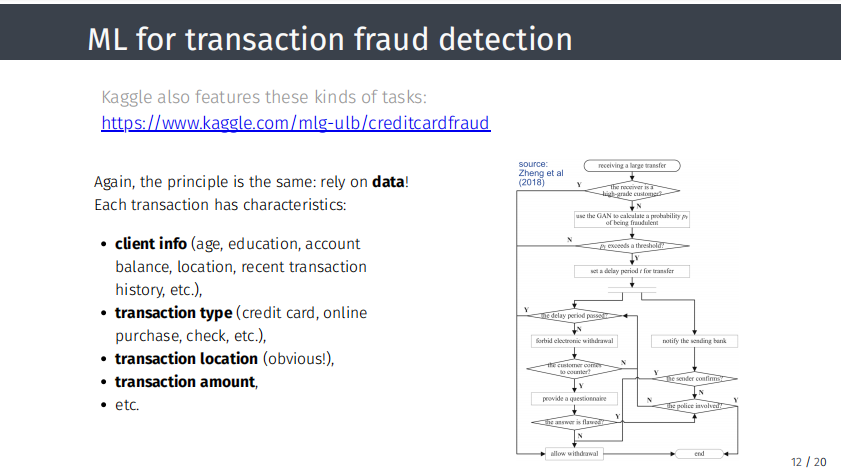
就像信用评分一样,为了进行欺诈检测,需要交易数据,因为通常与交易有关,包括交易的性质、明细和特征。其中包括客户信息,例如年龄、学历、账户余额、所在地点、最近的交易历史记录、交易类型、是否使用信用卡、是否在线购买、是否通过支票支付、交易发生地点、金额等等。

对于每笔交易,都可以获得大量数据,根据这些数据构建一个算法,尝试确定某项交易是否是属于欺诈。 一种简单的方法是确保一切顺利,即当前交易与过去交易类似。对于第二种交易,检测报告交易中是否存在欺诈的一种方法是求助于文本分析。可以尝试简单的文本挖掘,有时简单精确,例如根据数字频率。如果更有经验,则可以采用更复杂、更深入的工作,例如自然语言处理。

在这种情况下,道德问题较少,由于我们要避免欺诈,因此总体是合理合法的。但有一个重要的技术障碍,即拥有和收集的数据非常不平衡。在银行的所有交易中,只有极少数属于欺诈,因此在所有数据中,实际上只有很小一部分有用,包含大量信息。这造成一定程度的技术障碍和困难,但同样也有很多方法可以规避或解决这些问题。
三、资产分配

如今我们能够访问很多数据,实际上数据已经是理财行业中的业务。与公司开展业务时,会获得很多信息,包括公司特定数据,包括彭博、汤森路透以及类似的数据运营商报告的会计数据。此外,最近出现的新话题是替代数据,包括情感数据,通过自然语言处理计算,从社交媒体中提取数据。因此,在直播公司活动时,可以看到公众对公司新闻、公告、收益以及类似情况的反应。还可以访问市场上的高频数据,如果从事特定市场,高频可能意味着非常高的频率,例如毫秒级别。如果想尝试预测宏观经济水平将发生的情况,也可以在复杂模型中纳入宏观经济变量。
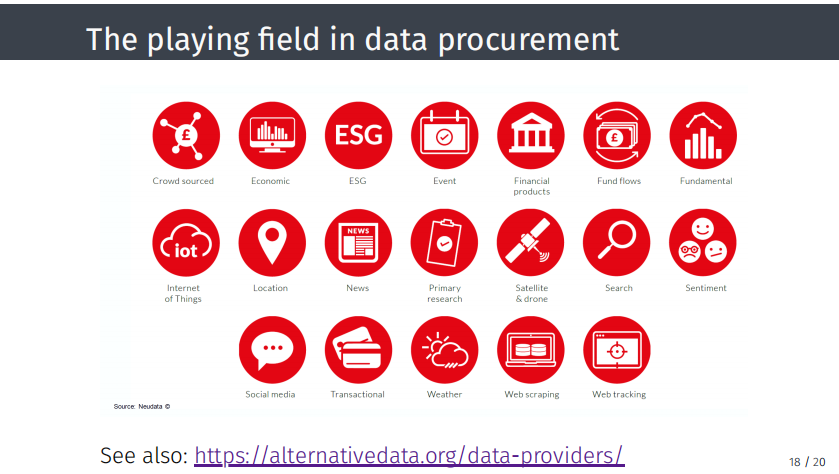
还有其他一些类型的数据,超出上述范围。例如,卫星图像可以用来查看中东港口、辅助石油行业的工作;查看沃尔玛和超市停车场的卫星图像,了解人们是否外出消费;通过超市的信用目录试图了解消费者的消费习惯和趋势;企业可以预测会发生什么情况,并以某种方式尝试从中产生利润。因此,数据获取领域前景广阔。

资产分配领域存在哪些问题?同样涉及市场投机行为,道德问题十分复杂。如今,人们日益严肃对待这个问题,这就是ESG投资蒸蒸日上的原因。 ESG与道德投资有关,也是最近的一大主题。此外,利用数据来产生利润也非常困难,因为经济环境总是在变化,很难尝试从过去的模式中推断未来的模式。此外还有回测问题、信任问题。这与信用评分中存在的问题相同。人们希望能够了解模型内部正在发生的情况。
以上是人工智能和监督学习技术在金融行业中的一些用例。金融行业中的机器学习是一个正在蓬勃发展的研究领域,相信未来将会有更多研究成果出现。
- 研究报告
- 农业
- 采矿
- 制造
- 食品饮料
- 烟草
- 鞋服纺织
- 家居家具
- 化工
- 钢铁
- 机械装备
- 汽车
- 能源化工
- 建筑
- 批发零售
- 交通物流
- 住宿餐饮
- IT/互联网
- 通信
- 软件信息




推荐

当前,生成式人工智能催生和引领新一轮科技革命和产业变革。

科幻电影「Her」的剧情正在成为现实。
企业如何来制定符合自身管理特色的数字化成熟度模型?
制造业上市公司进行数字化转型具有明显优势。
今年最受全国年轻人追捧的一个东北文旅网红是一只“猴”。

新职业数字化管理师的诞生,被认为是整体经济发展步入新阶段的必然选择。




 14417
14417 14625
14625 16844
16844 15986
15986 14446
14446 13026
13026




我要评论