

硅谷大数据科学家:标准化数据产品有哪些典型架构?|微课干货
-
修平平
-
2015-10-13
如果想要了解数据产品的典型架构,首先要还原什么是传统产品的典型架构。搞互联网的可能都应知道Restful,即表征状态传输的概念。基本的机身是http的请求是没有内部状态的。那么我在http请求里面,通过一些参数指定提交请求之后,返回的内容是确定性的。优势在于可以把产品做的规模化、适应流量增加达到互联网的规模的时候,仍然能够适应。

这里给大家一个案例。
这是一个非常知名的互联网的企业。它以提供某个行业非常正统的信息服务给消费者。主要流量是以浏览的形式。用户在它的网页上去欣赏它的内容。它的背后就是表征状态传输的架构。我们今天通过该课程来对其传输的过程进行描述。
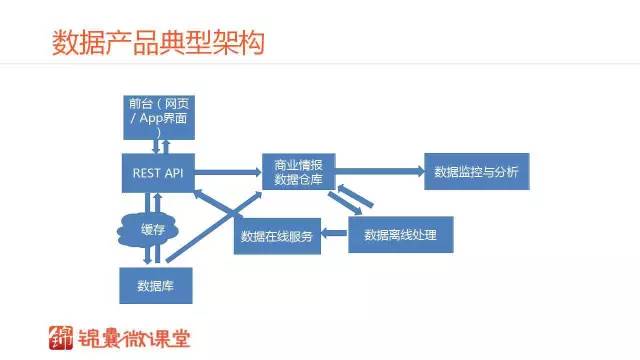
这是我理解中数据产品的典型的组件。相对传统的表征状态传输的架构,它几乎具有所有的表征状态传输的架构。包括前端、后端、API层、缓存层以及数据库层。还有数据相关的四个组件是数据仓库、商业情报、数据监控与分析、数据离线处理和数据在线服务。

这几个层有不同的作用。商业情报层主要是管信息整合,数据监控与分析层管运营,数据离线处理是信息的二次加工,数据在线服务是数据驱动产品体验。这几个层是数据产品能够转起来的最基本的组件。稍后我会结合案例进行深入分析,现在我们先来看一看每个层的作用。

商业情报层是数据仓库,是一种特殊的数据库。是专门用于做数据分析和决策的数据库。它和传统的数据库有本质的区别。传统的数据库,它的ER设计是一个现实过程的还原。所以你看到ER图之后,你就能够知道它的过程、流程到底是什么。最主要特点是高度正则化。
商业情报系统是大数据技术的典型应用场景。之后的一些大数据的技术都是受商业情报系统设计的一些启发。最知名的参考书就是《数据仓库工具箱》。它的核心概念是数据仓库或者商城系统是提高商业决策的基础。他的数据表在设计的时候是动态变化、可拓展性的。就是为了做数据分析。这个和ER的设计概念完全不一样。它的数据表结构的设计原则是为了查询简化和数据的复用。能够支持敏捷的做各种各样的数据之间关联性的调查。

在商业情报的基础上,我们还有数据监控与分析层。在大数据时代之前,数据监控与分析的主要工具就是Excel。具体的说就是透视表和回归分析工具。那么R就是统计分析标准语言,适合做模型的评估比较。对相关人员的技能要求高是因为需要做一些建模。
一些基于Web的服务能够使大家实现对数据可视化、实时化与共享性。我列出来的一些都是在大数据时代做数据监控与分析的典型的第三方Web Service。比如,有一些是适合做商业高层数据的分析的。Google Analytics是做广告的。Splunk是做点击优化与网站内容优化的。还有AppDynamics是负责网站运营、运行监控的。它的特点的更多的人员能够参与到数据分析之中。不管是公司的高级管理人员还是运营、网站监控、数据分析师都能使用一套工具来进行数据分析和共享。

数据离线处理一定要提到Google的三驾马车。Google在十年之前陆续发表了三大经典论文。这是进入大数据的时代的标志。GFS就是使用非高端硬件实现大数据存储。MapReduce (大排序)归并排序MergeSort应用在小内存。BigTable准关系数据库,支持宽表(Wide Table), 列簇(Column Families);适合数据仓库。
当时最主要的时代背景是大量的非高端硬件普及。非高端的硬件实现了非常可靠的数据存储。排序技术是最主要的数据分析引擎。MapReduce 是最本质的一种排序,归并排序。
那么哪一点是新的呢?本质上说都是原来的技术,只不过是在硬件上实现了突破。其实排序技术是最古老的算法。它能够使大量硬件在小内存实现规模化。这一点就奠定了大数据时代。其实在上层,所有的数据分析都可以归结为排序算法。
所有的数据分析,如果在排序上面能够做得非常规模化,能够处理非常大的数据量,那么所有的上层应用,数据分析都能够做得非常棒。从这一点上说,大数据技术并非非常神秘。本质上都是历史上已经有的技术,因为现在硬件的突破使得我们现在能够处理非常大的数据集。

Google的这些技术已经有十多年的历史了。随着技术的进步,产业出现了一些新的环境。比如内存的发展,我们现在有了更多的内存,可以有更多的优化空间。另外从商业来说,实时性的要求提高了。最典型的就是社交网络,尤其是微信和Twitter这些都要求实时性的提高。所以近年来流计算技术(Streaming)的发展就是最近新出现的技术。它其实就是对数据排序的优化。
因为我们现在有了更多的内存了,所以MapReduce的一个操作运行完都写在磁盘上,对于数据的重复使用上是不优化的。实际上,很多MapReduce是在一起运行的,所以就存在很多的优化空间。就是我现在内存中的数据可以不写回硬盘,但是可以执行下一个操作。
同时MapReduce并没有考虑到实时性的需求。由此产生了Storm。Storm和Spark不一样,数据是在内存中以实时流的形式,在预先设定的拓扑中流动。其实MapReduc很大的瓶颈是在对数据发生扭曲的时候,一些实时性的问题。Storm对实时性的优化实现了对MapReduce在实时性上的优化。
一、机器学习

刚才说的是大数据,还有一种离线处理是机器学习。机器学习在数据产品中的作用就是从历史海量数据中学习规律。这种规律的是以模型的形式存在。它能够推送在线上,在线上环境中快速生成决策。
机器学习这一门学问是博大精深。有半个世纪的发展和很多算法。在商业应用中主要是做决策树和逻辑回归。决策树适合在样本少量的情况下,便于调试。我们最先开始引入机器学习技术,那么建议先用决策树。Vappal Wabbit是一种逻辑回归工具,偏重于自然语言理解,需要大量样本。最主要的优势在于用单机就可以运行,能处理非常大的数据集。
二、在线服务

传统的在线服务就是RESTful API,主要就是数据库+缓存。因为数据是需要更新的,需要适应动态变化。更新机制传统的最简单的就是清除缓存,重新查询数据库,还有基于批处理和消息队列。那么在大数据时代,最主要的在线服务就是通过Key-Value Store。这也是最古老的一种数据结构。
现在一些非常知名的开源的软件,比如 S3,DynamoDB,Cassanda。本质上其实都是在online的时候能够实现非常可靠的、规模性的一些Key-Value Store的查找。
回到我们最开始的案例。这个传统企业有一些内容是通过数据库的形式存在。需要通过规模化提供Web的服务。它采用了Restful这种典型的架构。这是有痛点的。比如,我在前台的时候,需要有许多的用户需求。其实后台是需要服务于前台的。前台需要用户不断的提出新的页面需求。意味着数据通过新的呈现方式展现。这个对后台的压力非常大,因为后台不能直接通过正则化的数据库服务出去。你需要通过一些中间的数据表,是去正则化的。是为了前台去定制的,说这就带来了很复杂的后台。还要保证正则化的表和非正则化的表之间的怎么去数据,才能够达到一致性的问题。这就使得他们越来越慢,越来越多的开发都在后台上。
现在大数据时代到来了。我们提到了这么多组件。这个企业是怎么转型的呢?首先是在离线处理的这个模块,把数据库从正则化的数据库直接用离线处理大数据的平台去做好前台的网页。从中间的数据库去正则化的表都用大数据生成了。所以第一个阶段取得的成果在于极大的简化了后台。是大数据的离线处理使得我不需要维护非常复杂的后台就能够支持前台。因为我的后台处理就是MapReduce的技术来实现的。
有一个很坏的事,他又进入了下一个痛点。每一次改了正则化的数据库都需要等一天的时间。因为离线处理是每天执行一次的。每天最新的更新需要积攒起来等下一班的数据离线处理,才能够推送给服务端。不能很快的去响应用户的需求。
所以为了让实时性的要求提高。它又采用了数据在线服务方面的Key-Value Store。那么它通过消息队列把后排当中数据库的变化消息能够在查找表中得到更新。在API层,会现在查找表中去检查是不是最新的更新。如果是最新更新就直接从在内存中的查找表返回数据。否则,就会在到批处理的数据中找到返回数据。所以还是需要离线处理,但是应用了在线的查找表,把时间缩短到了几分钟之内。
这是一个比较好的转型。在线额离线处理结合。首先通过离线处理使后台得到了极大的简化。同时又使用在线服务,实现了快速在服务端显示后台更新。结合之下,达到了真正的数据产品。这是一个典型的案例,最核心的就是从离线处理出发。但是离线处理需要一个非常好的数据源。所以一定要把你的商业情报和数据仓库这一层设计好。然后使用一些第三方应用去实现数据的实时监控。
同时最挑战的是怎么把离线处理的结果推送到在线?实现的是数据的在线服务。这里面有一些机器学习的成分。一般的策略就是从简单的、经典的学习算法入手了,逐渐根据需求上更加复杂和更大的数据输入才能转起来的算法,比如深度学习。
文章为「锦囊专家」原创作品,欢迎转载。作者: 修平平。
- 案例
- IT/互联网
- 软件信息
- CEO
- CTO
- CDO
- IT
- 大数据
- 协同办公
推荐
 32957
32957 18435
18435 17332
17332 22502
22502 19481
19481 16751
16751




我要评论